
A Scalable Pipeline For Your Commercial Microfluidic Workflow
Operating microfluidic testing at a commercial scale generates large volumes of data, primarily images, setting it apart from most lab tests. Some tests can generate thousands of .TIFF images and multiple sensor logs each with thousands of points. Managing this data through a robust pipeline is critical for a lab to be able to reach commercially viable throughput.
This blog explores the data management problems associated with running commercial volumes of microfluidic tests and outlines the approach that we, at Interface Fluidics, are using to wrangle this data.
To connect this issue to something familiar, consider how we stored images in the early 2000s. Maybe you were still storing physical photos in shoe boxes, but if you shot digital, all the images had to be manually transferred from your camera to your PC where they were stored locally. The ability to remember where the pictures were taken, and with which camera, was as good as your ability to commit to labeling subfolders and folders with the relevant names. Now with products like iPhoto and Google Photos, images are uploaded automatically with the relevant metadata saved automatically. You can go back to the pictures you took and remember if they were in Dallas or Houston Texas, and what year they were from, with the click of a button. The challenge of a microfluidic workflow is more extreme, all images look nearly identical to even a trained eye and labeling images is critical for them to retain their value.
First off, what do I mean by a commercial volume of microfluidic tests?
In an academic setting, a single researcher often handles test planning, execution, and analysis over a period of several months. Since one person is managing the project and detailed record-keeping becomes less critical after publication, this data often disappears once the researcher graduates.
In a commercial lab, there is usually a division of labor between the person designing the testing program and the person executing the tests. Often multiple equipment operators on multiple instruments are needed to complete a test program on time. A throughput of at least one test per day is common. An organized method of storing data becomes essential.
There are a number of reasons that storing information in a well-structured database is important. As companies move toward implementing artificial intelligence solutions, those with the most training data will win. The ability to rapidly conduct either manual or AI analysis on the entire corpus of a company’s testing can bring forward new insights that make them more competitive.
Here is the data that Interface Fluidics captures in a typical microfluidic test
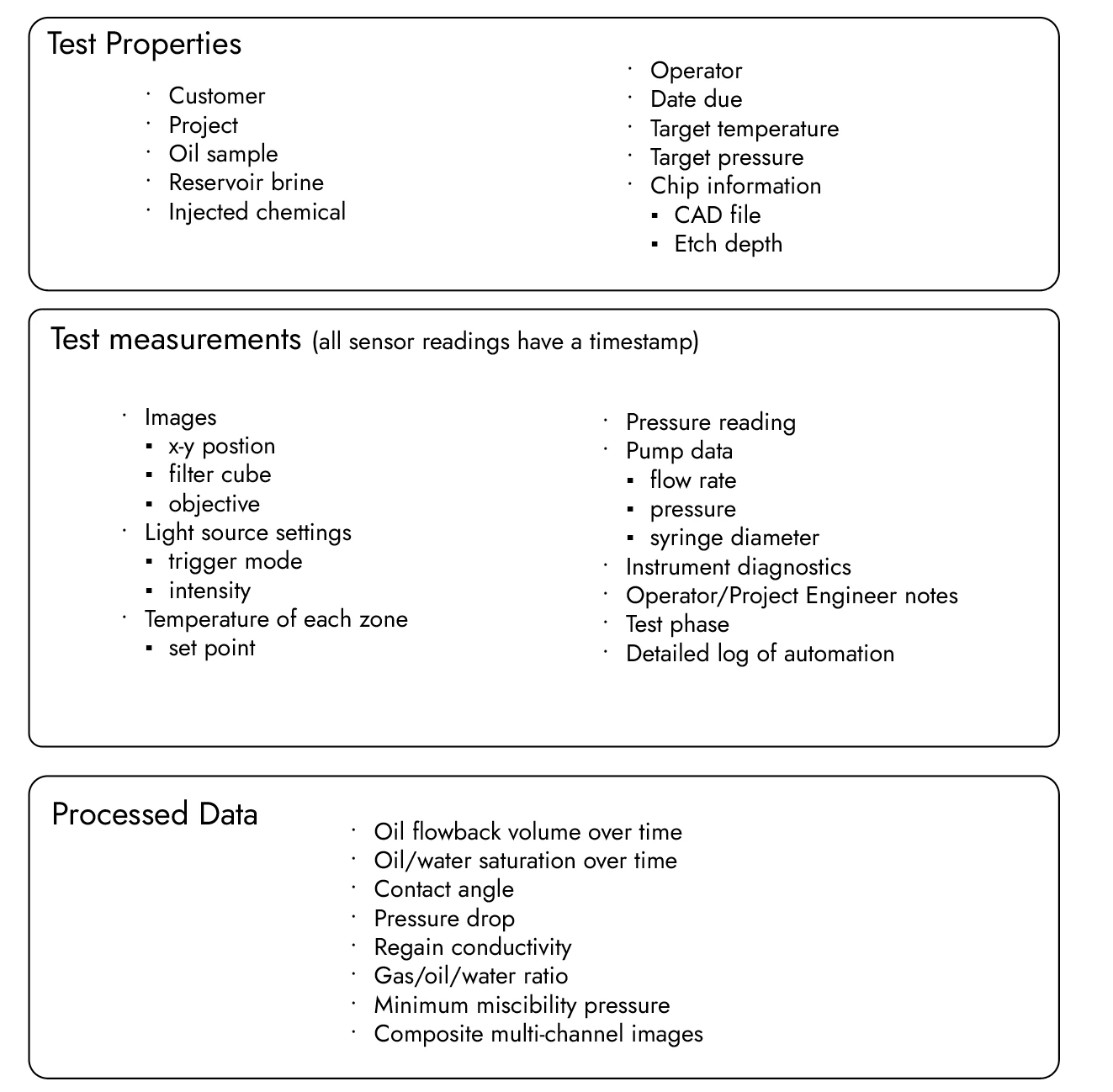
When your lab is recording all of the above measurements for one or more tests per day, the volume of data can quickly reach the terabyte level. If you are manually labeling image files and sensor logs, one error can invalidate a day’s work easily.
Previous workflow
The workflow that Interface used before we built the data pipeline for our SapphireLab® systems was as follows:
Images:
- Captured with open-source microscope software and labeled in an accepted format that included the objective used, the test name, the filter used and other relevant information.
- Stored in a file directory in our network attached storage drive.
- Merged and processed on a computer in the office with multiple intermediate copies saved to disk (this makes the volume of stored information much larger than the original images).
- Data compiled in an Excel spreadsheet.
Sensor logs:
- Because it was time consuming, only the most critical logs were saved—usually pressure logs. Many logs were not recorded or recorded manually in notebooks (like temperature setpoints).
- The Project Engineer needs to manually line up the sensor log timestamps with the image timestamps. This can be error-prone because it can depend on the assumption that images are captured at a regular interval.
- The compiled sensor logs and data from processed images are plotted and then exported to final reports.
The above process led to many lost days of effort in the lab, a ballooning network drive with many intermediate image stacks saved, no ability to easily compare the data between projects, and many sensor logs that are not saved, or saved in laboratory notebooks, never to be seen again. We also found that the amount of information that was sometimes needed to accurately store metadata in image filenames exceeded the allowable character limit for Microsoft Windows.
It was obvious—we had to find a better solution.
The SapphireLab® Data Pipeline
When building the data pipeline for our SapphireLab® systems, we had the opportunity to use a modern toolset that allows our clients to break down data silos and support the pace and complexity that is required in the modern energy industry laboratory.
The goals of the SapphireLab® data pipeline are:
- Build a secure unified database of your company’s data so that it can be quickly queried
- Reduce labeling errors and errors of omission when storing images and sensor logs
- Eliminate duplicate data that results from manual copying of images
- Enable staff to access data from any secure web browser with appropriate credentials
- Ensure data security through redundant cloud storage
- Maintain operations through extended periods of internet outage
The three core software components of the SapphireLab® data pipeline (all produced by Interface Fluidics) are:
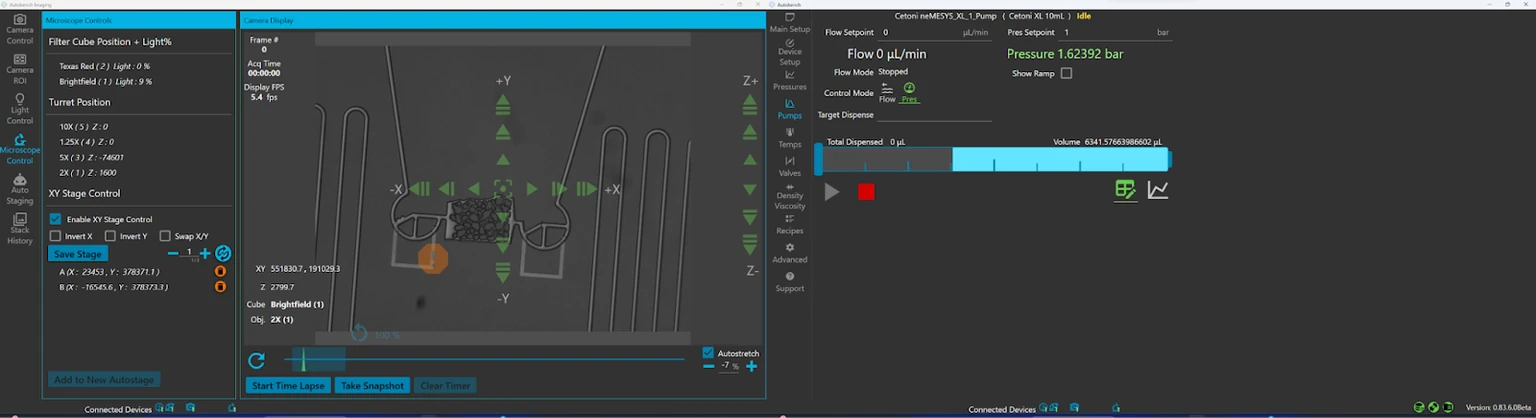
Autobench
- Desktop software for capturing data from microfluidic tests, to run automation “recipes”–pre-canned automated test procedures–and provide a central control system for the SapphireLab® hardware.
- The Operator assigns chemicals and chips to tests and can then run automated recipes created in Portal.
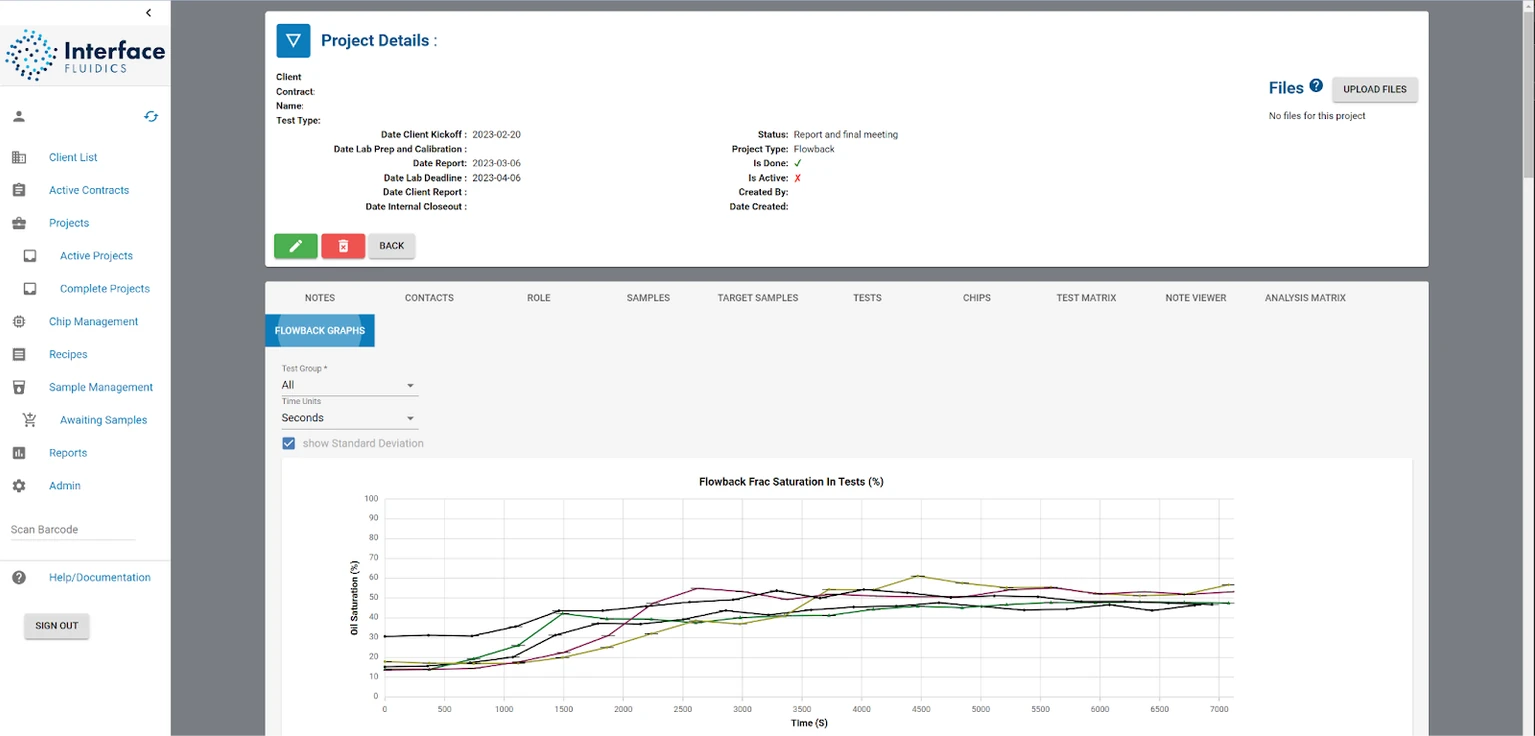
Portal
A web-based central location for planning test matrices – the series of tests that will make up a given project or experiment – as well as referencing electronic lab notes, managing sample inventory, building automation recipes, and reviewing raw and processed data.
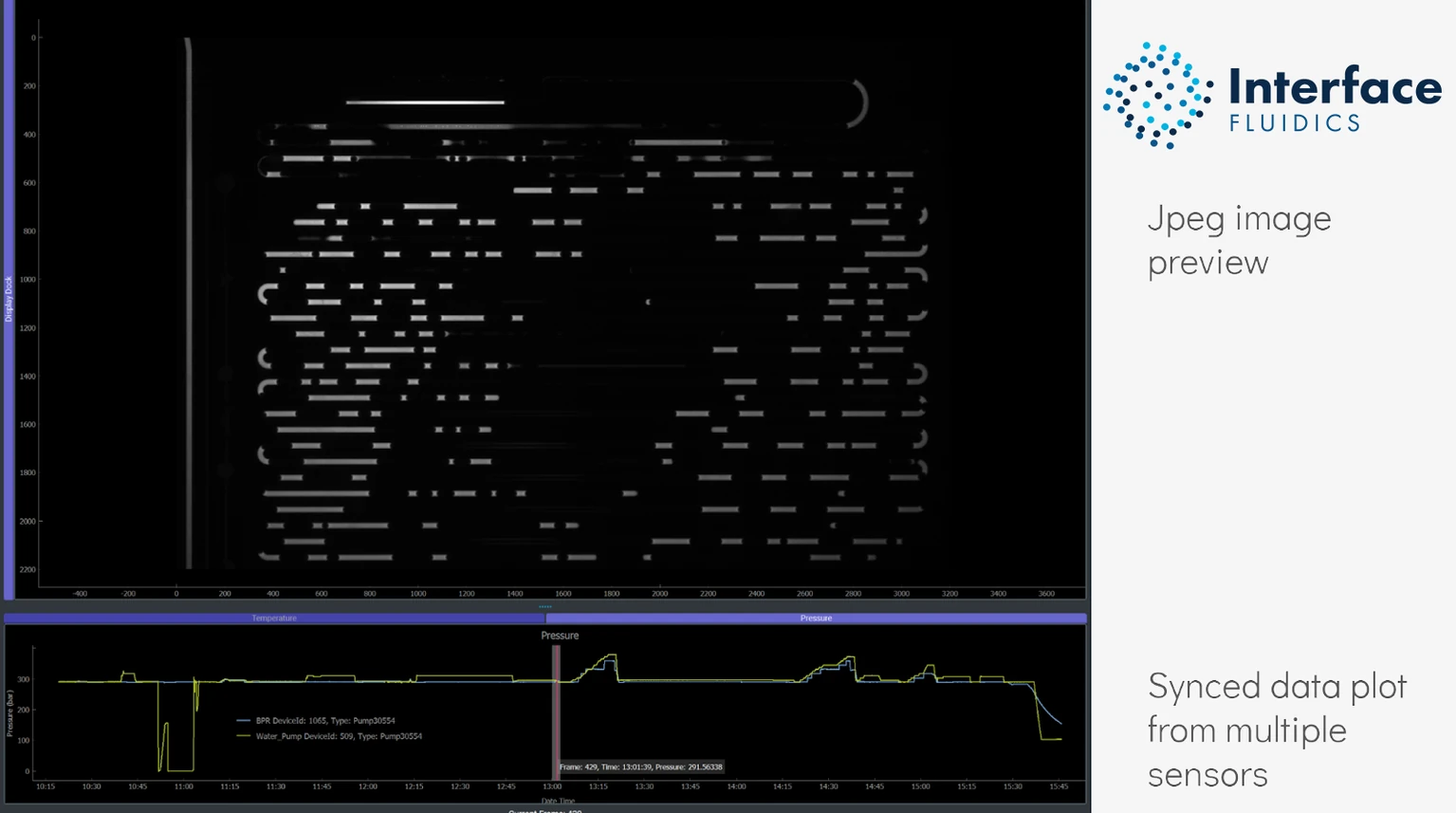
Autoanalysis
- A desktop application that allows for the detailed manipulation and review of images and sensor logs and the automation of image analysis
- Processed results are accessible through Portal for later review
System architecture
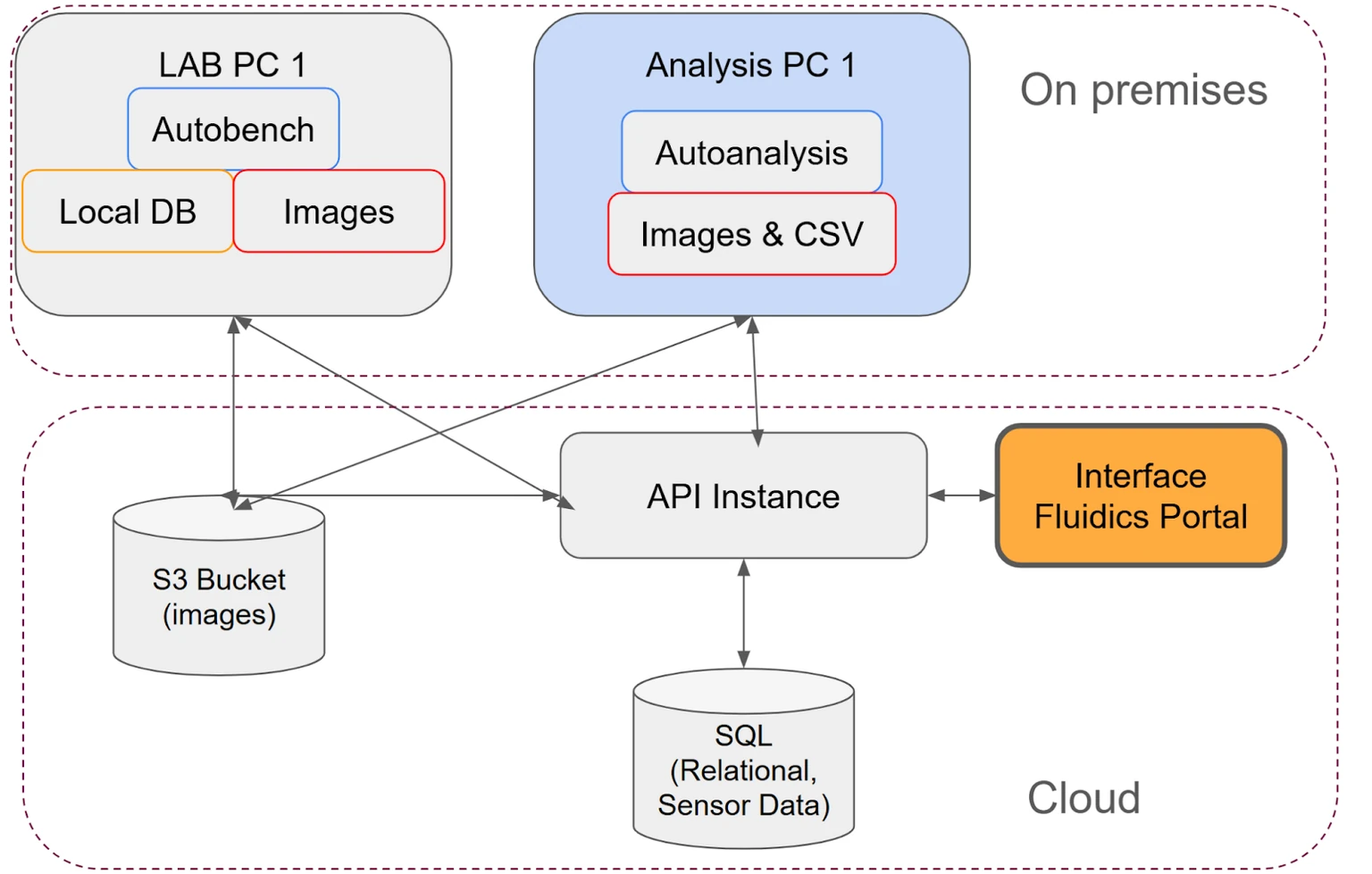
The system architecture is designed with classic cloud-computing components at its core, including elements typical of a LIMS system, while retaining the ability to remain offline and operate in conditions of poor network performance, while having a high data collection rate. A key consideration is that the data rate at which a modern microscope camera is capable of capturing images can exceed a typical internet uplink by an order of magnitude, at least for a short period of time.
As more SapphireLab® units are added, all data is stored in a central repository for your company. You can operate SapphireLab® units in multiple labs around the world and have all data in one central location.
This design also allows for the separation of concerns between the Operator running the experiment, and the Project Engineer, planning the test and analysing the results.
SapphireLab® workflow
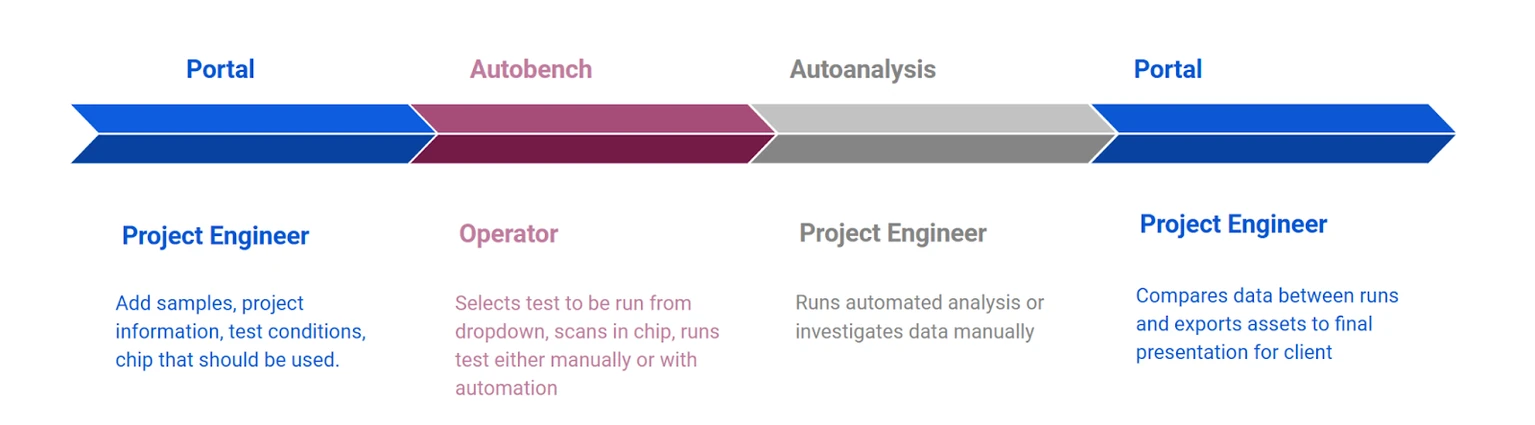
The SapphireLab® workflow separates the tasks of the instrument operator and Project Engineer. We found that often these two people may be located remotely from each other, so the system allows for the Project Engineer to plan tests and analyze data from anywhere they have access to a secure PC with the needed credentials.
The role of the Project Engineer is to design the tests to be done in a given project. They will add the samples that are used, the desired operating conditions, the type of test, and the chip parameters. This information is accessible by the Operator through Autoanalysis.
The Operator loads the planned fluids and a chip of the correct design according to the requirements of the test matrix. They can then either run the test manually according to the standard operating procedure, or automatically through the recipes that are built in the Portal.
Once the test is complete, all the images and sensor data are uploaded to the secure cloud platform with universal timestamps and complete metadata. The Project Engineer can review the data in Autoanalysis and run automated analysis recipes. The processed data is uploaded to the cloud.
Once the project is complete, the Project Engineer can customize the plots and export them as images or .csv files for further analysis. The data will be readily accessible at any point in the future that the Engineer wants to reference and compare the results of a new test with past data.
As a company adds more SapphireLab® hardware units, all the systems write data to one unified system that can be managed by a single engineer through Portal.
Example of SapphireLab® Workflow
Alex the Project Engineer, who works for a new chemical provider, has been handed a project to optimize the chemical composition of the hydraulic fracturing fluid blend in a well their customer is completing next month. They have four candidate chemistries and are looking at two potential loadings: 0.5 gallons per thousand (GPT) and 1.5 GPT. The client has sent samples of the oil from the reservoir and the composition of the reservoir brine and water that will be blended with the chemistry. Alex has also been sent the reservoir temperature and rock properties. She is based in Austin and the company laboratory is in the Woodlands. Each user has different permissions in the system and can change the parameters best suited to their role.
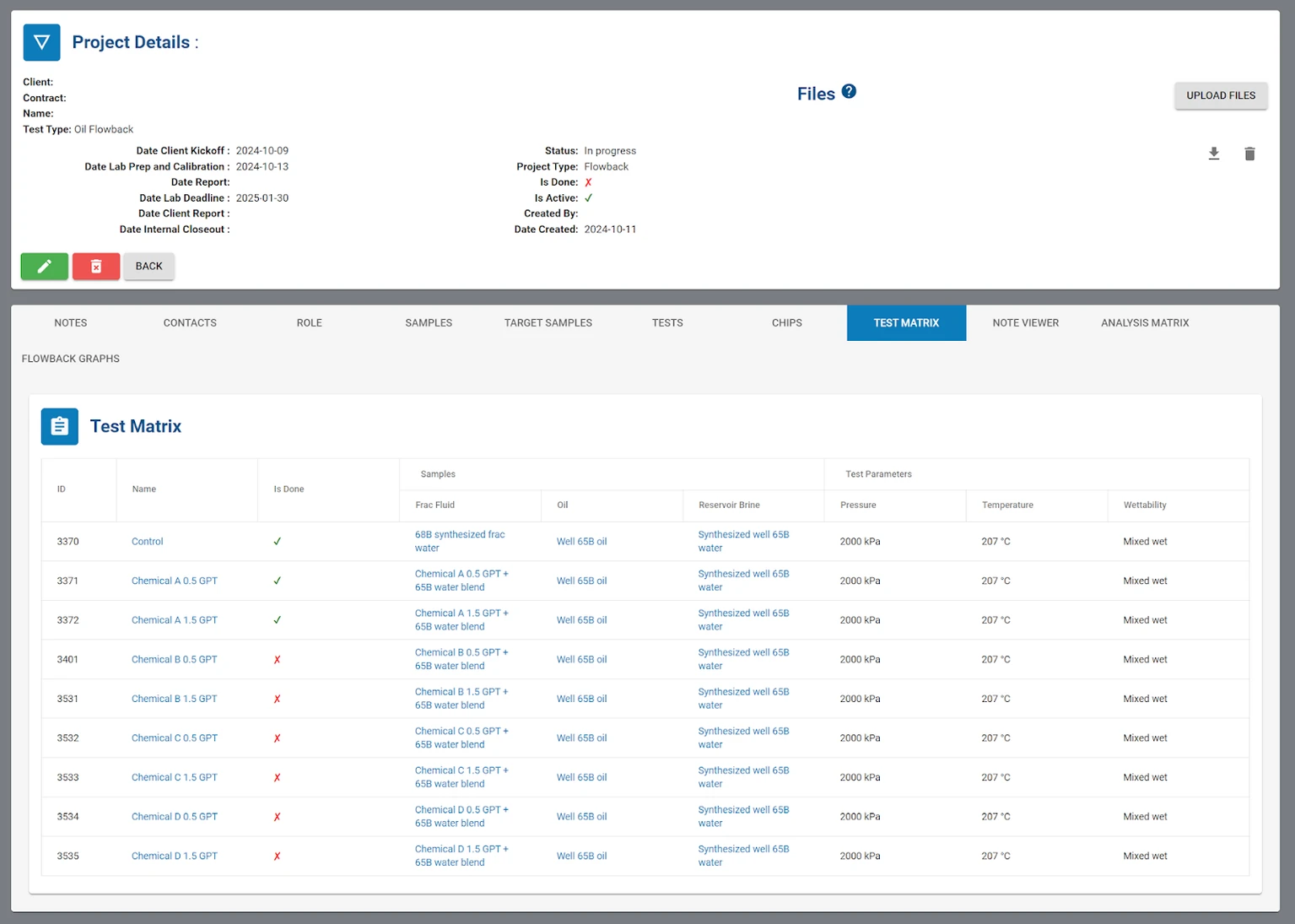
Alex opens her web browser and logs into Portal. She already has the salts that comprise both brines loaded into the system, so she adds the oil sample and the four chemicals with the SDS sheets. She creates a new Flowback project under the client and starts to map out the test matrix. She makes a table with all the parameters that she wants to test:
Doug in the Woodlands lab has just finished a big 78 test project for another client and is looking forward to a break, alas he gets a Teams message from Alex that she wants to have a call about a new project. Back to work. They discuss the goals of the project and review the test matrix together. Doug synthesizes the brine samples according to the composition that Alex put in the portal and prepares the oil sample that was shipped in last week.
Doug opens Autobench, the system is clean and ready to run after finishing the last project. He selects the project that he wants to run, the test, scans in the chip, verifies the fluids, and starts setting up SapphireLab®. He fills up the syringes, loads the chips, and starts running the Flowback test according to the standard operating procedure.
Back in Austin, Alex can see the images as they are taken and the current pressure and temperature of SapphireLab® via Portal. They have a few video calls over the week to sort out a few unexpected fluid compatibility issues, which they will need to discuss with the client. Luckily, they have two SapphireLab® systems so they can complete the 10 tests in one week. They had a 30-minute internet outage on Tuesday but, luckily, Autobench wrote the results to the local cache and uploaded them when the internet came back on so nothing was lost.
Alex loads up Autoanalysis and, in a few minutes, has all ten tests queued up for processing. She loads up Portal and can see the results populate the table and graphs. The results look familiar to something she saw 3 years ago; she searches for that project and looks at some of the images and plots, this used to take forever with the old system. She copies a few of these over to a PowerPoint she is working on and heads home for the night. The big presentation of the results with the client is tomorrow.
Conclusion
The SapphireLab® data pipeline was built in response to real problems that we saw at both our customers’ laboratory operations and our own. The SapphireLab® data pipeline is a cloud-native platform that is built for scale. As users add more SapphireLab® systems, the system grows with them. There is no need to shuttle data around on external hard drives between the lab and the office—the system can easily handle terabyte-level data. The hard drive on SapphireLab® will not fill up because data is uploaded to the cloud.
We realize that a well-built database is a critical asset of any institution as they grow and adapt to new technologies like machine learning and artificial intelligence. The most competitive companies of the future will be those that learn from their mistakes, build institutional knowledge, breakdown data silos, and move quickly.
The SapphireLab® data pipeline can help your company be more competitive in the new data-hungry world, where being able to access, preview, and compare data from multiple projects quickly can be the thing that makes the difference between winning and losing bids. Whether you’re operating a single instrument or a network of labs, SapphireLab® is the solution for modernizing your microfluidic workflows.
Contact Us to learn how SapphireLab® can revolutionize your lab, and stay tuned for upcoming blog posts that explore each software package in detail!
Watch How it Works
Interface Fluidics Portal Project Page
Explore our client portal designed for seamless access, control, and analysis of your microfluidics test data. This short demo showcases how the Portal Project simplifies data visualization, streamlines workflows, and enhances your microfluidic system experience.
Interface Fluidics Portal Chemical Inventory
Explore our client portal designed for seamless access, control, and analysis of your microfluidics test data. This short demo showcases how the chemical inventory enables for detailed records of chemicals used in each test. Ask & learn
Interface Fluidics Portal Image Preview
Preview and download your high resolution and raw images from your tests
